Research Project Organisation
Overview
Teaching: 10 min
Exercises: 5 minQuestions
How to organise project folders?
Where and how to save different types of files?
Should I version control my data?
Objectives
Build folder structure for a new project
Understand where to save scripts, data, and other project files.
Understand when to version data.
Understand how to ignore data files with git.
Getting organized
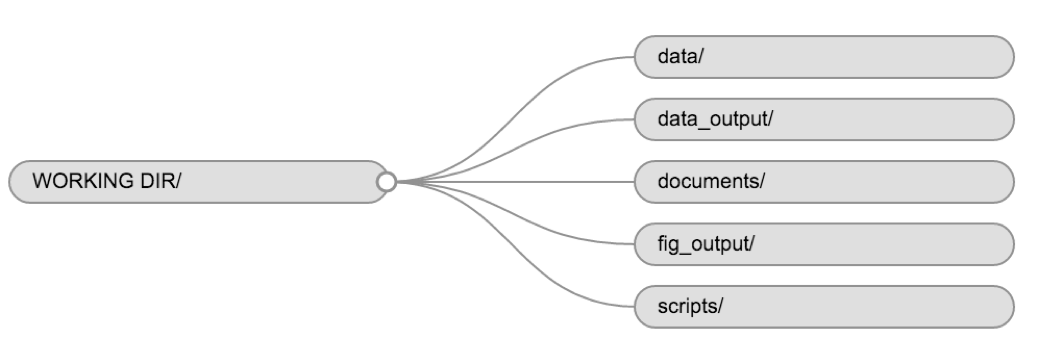
Using a consistent folder structure across your projects will help keep things organized, and will also make it easy to find/file things in the future. This can be especially helpful when you have multiple projects. In general, you may create directories (folders) for scripts, data, and documents.
data/Use this folder to store your raw data and intermediate datasets you may create for the need of a particular analysis. For the sake of transparency and provenance, you should always keep a copy of your raw data accessible and do as much of your data cleanup and preprocessing programmatically (i.e., with scripts, rather than manually) as possible.data_output/When you need to modify your raw data for your analyses, it might be useful to store the modified versions of the datasets generated by your scripts in a different folder.documents/This would be a place to keep outlines, drafts, and other text.fig_output/This folder will store the graphics that are generated by your scripts.scripts/This would be the location to keep your R scripts for different analyses or plotting.
You may want additional directories or subdirectories depending on your project needs, but these should form the backbone of your working directory.
Let’s create a folder structure now.
- In the
Filestab of the lower right hand pane of RStudio, click on theNew Folderbutton. - Create a folder named
data - Repeat to create another folder called
scripts, and another calledfig_output. - As you progress through your project, you may wish to create additional folders, such as
resultsordocuments. For this workshop, we will focus on R-related folders like Data, Scripts, and Figures.
Since we already have a script, let’s move it into our scripts folder.
- Tick the checkbox next to
Git_Setup.Rin theFilestab. - In the top bar, click
More>Move.... - In the popup window, navigate to the
scriptsfolder and clickSave.
From now on, be careful to save any files in the appropriate folder. It will make everything much easier to find. As we will see later, this also has advantages for proper version control.
When you name your directories, use clear, concise names. It is also a good idea to avoid spaces and special characters. Although newer versions of R deal with these pretty well, weird filenames can sometimes cause confusing errors that take a long time to track down.
Scripts and Data
The first major step after setting up a project is usually acquiring data for your project. You may have data in an excel spreadsheet, data that was formatted by some other piece of software, or data downloaded from the internet. Whatever format it is in, save the raw data inside your data folder. You should never directly alter or edit your raw data in any way. When you want to clean or reorganise your data, you should always make a copy first.
Let’s get some data to put in our Data folder. Create a new script by clicking File > New File > R Script
Paste or type the following code into the empty file that opens.
download.file(url = "https://mq-software-carpentry.github.io/R-git-for-research/data/SAFI_messy.xlsx", destfile = "./data/SAFI_messy.xlsx", mode = "wb")
Be sure to save your new script File > Save As. Let’s name our script Data_Downloads.R and save it in our scripts folder. Place your cursor on the line of code and click Run to download the data.
If you write R code to retrieve your data, the way we have done here, it will be easier to figure out the source of the data later. Alternatively, you may choose to download data manually, but be sure to make note of the source of the data (perhaps in a text file or in your code’s comments). Most computers automatically put downloaded files into the system’s Downloads folder. If you decide to manually download data files, you will need to make sure they are moved to the data folder in your project directory.
Ignoring stuff
Your raw data will remain the way it is, so there is no point in versioning it. GitHub is not a data repository and does not allow the upload of large data files. Furthermore, if you are working with sensitive data (such as personal identifiable data), it should never be uploaded to GitHub anyway! Be mindful what sort of data you upload.
Data can be stored on GitHub if it’s a small, public dataset. One solution is to publish your data in an online data repository, then provide code that will allow authorised users to access it (for example, the way we just did above). There are other solutions, but they will vary depending on your specific project and data.
For the purposes of demonstration, let’s make sure that our git repository does not track our raw data files.
- Highlight (do NOT tick the checkbox) the data file in the Git tab by clicking on it.
- Click
More>Ignorein the top bar. - In the dialogue box, you should see that the word
datahas been added to an existing list of entries. This will ensure that the data folder will not be tracked by git. - Git can be taught to ignore entire folders, file types (e.g. *.csv), and specific files. If you have your raw data files in a
datafolder, typing the name of the folder will do the trick.
There are several other reasons to tell git to ignore a file. Some systems produce machine-specific files that will not work on another computer. (for example, “.DS_Store” on Macs). When you close R Studio, if you choose to save your environment, R will produce .RHistory and .RData files that back up (potentially gigabytes!) of data from your workspace. Tracking these is not a good idea.
Have a look at your project directory in the Files tab in the lower right hand panel. You should see a file called .gitignore. This is where git stores information about what files NOT to track. Notice that R Studio has automatically added its .Rdata and .Rhistory files to the list of ignored files. At the bottom of the list, you should see our recent addition, “data”.
Because we have edited our .gitignore file, we need to save, commit, and push our changes before moving on. We also need to commit our Git_Setup.R script once more, because its location has changed. If you tick the checkboxes next to Git_Setup.R and scripts, Git should recognise that the file has simply been moved. This is indicated by the purple square with R written in it that shows up once both items have been ticked. R stands for “renamed”.
Key Points
Build and maintain a project directory that is easy to navigate.
Understand when and how to